Complexity Simplified
Engine for high-speed scanning and transforming data at scale
- Collect detailed metadata in single-pass
- Easily customizable via UDF
- No learning curve: PostgreSQL-compatible SQL
Highlights
- Simplicity: No requirements for query-aware data models (star-schema) or data placement (distribution key, sort key): performance out-of-the-box
- Scale: Scale up or out, indpendently scale compute and storage
- Speed: Very fast ingest and execution of complex SQL on high volume data
Parallel Everything Architecture
Like many competitors, XtremeData began with an open-source database software package. But unlike others, we then re-engineered the core query execution code with a truly parallel, vectorized SQL engine developed from first principles. The reasons for this are simple. Legacy database software, including all open-source packages, were developed decades ago and are not optimized for the key computing resources of today: many-core CPUs, large amounts of memory and high-speed networks.
Unlike “federated” systems, where multiple complete instances of a database run in parallel, XtremeData offers a single instance of a database that within itself contains a truly parallel SQL execution engine. The core software layer manages all peer-to-peer communication and data exchange between nodes. It has been designed to excel at what other databases find difficult or impossible to do: handle big data issues of complex SQL against complex schema. XtremeData is data model agnostic and does not require careful data partitioning or placement to deliver performance. This enables us to excel at performing complex n-way joins and aggregates against multiple big tables, at scales of 1-100's of TB.
At XtremeData we have benchmarked our engine against federation-based competitors and also against “NoSQL” solutions like Hive, and measured performance gains of 10x. What does this mean? Put simply, the federated systems will need 10x the hardware resources in order to match XtremeData.
Scale vertically and horizontally to meet workload requirements
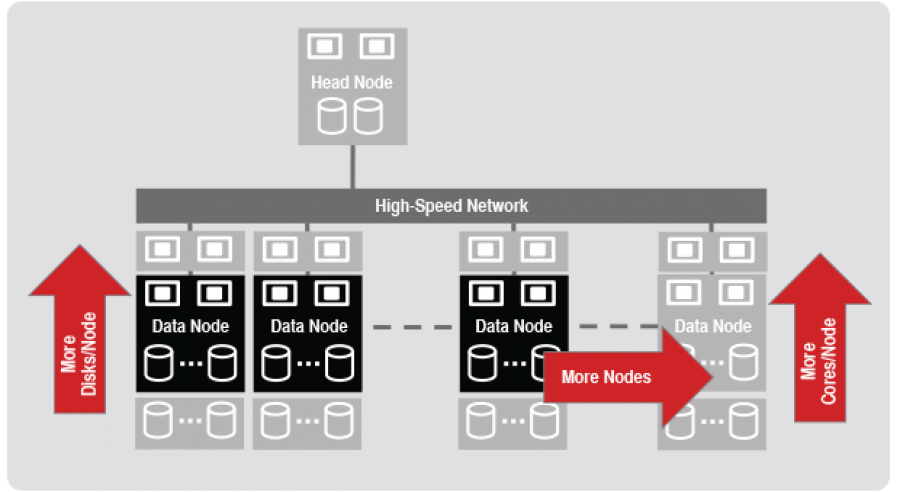
Decoupled from hardware, logical nodes can be mapped onto differently sized physical nodes, with different resources, such as the number of cores and disks. This enables customizing CPU-to-I/O ratios. And, systems can be scaled one node at a time to support growth.


XtremeData implements an innovative and highly efficient system for dynamically redistributing data as needed, using industry standard network technology. Data exchanges between nodes occur as peer-to-peer transient transfers at runtime for query needs. The data exchanges are carefully pipelined with processing stages, such that the transfer times on the network are effectively hidden and do not significantly affect query execution time. XtremeData ensures that all joins perform at near the speeds of co-located joins. Dynamic data redistribution eliminates the need for query aware data models and sympathetic placement of data, thus significantly reducing implementation time, labor and costs.
XtremeData allows users to simply "load and go" with any data model and any placement. No longer does a team of DBAs need to fully understand the usage patterns and try to match the placement with queries to obtain performance. XtremeData provides high performance out of the box, at all scales.
XtremeData allows users to simply "load and go" with any data model and any placement. No longer does a team of DBAs need to fully understand the usage patterns and try to match the placement with queries to obtain performance. XtremeData provides high performance out of the box, at all scales.
